
Surpreendeu-me como foi fácil construir uma solução local com Ollama.
Introdução
Essa vontade de ter uma solução privada para IA surgiu depois que vi que a OpenAI mudou suas configurações na seção playground e não permite que usuários gratuitos testem os modelos. Com isso, fui verificar o Gemini, mas era a mesma coisa. Ambos estão custando US$ 20/mês e, para mim, não vale a pena no momento. Por causa disso, comecei a procurar soluções privadas, já que já tinha visto pessoas executando soluções de IA localmente. Juntamente com o fato de ter adquirido um novo MacBook Air M2, decidi testar os limites.
Ollama
Ollama é a primeira tentativa para mim e funcionou perfeitamente. Você baixa e executa a partir do terminal com o comando ollama run llama2. Este comando fará o download do modelo llama2 e iniciará o programa com esse modelo já em execução. Este modelo específico tem cerca de 7 bilhões de parâmetros e um pouco mais de 3 GB de tamanho. Se você tiver uma conexão decente, é muito rápido. Eu o testei e foi surpreendentemente rápido. Em seguida, testei os modelos mistral e gemma.
O modelo mistral funcionou bem, mas o modelo gemma não rodou bem e, como não tive tempo de verificar o que estava errado, apenas verifiquei se havia uma solução e, de fato, parece haver uma, mas eu não a testei.
PrivateGPT
Esta é a segunda parte, que é um pouco mais difícil de implementar, mas fácil o suficiente para implementar uma Geração Aumentada por Recuperação (RAG), o que basicamente significa que você pode fornecer os arquivos de origem para serem ingeridos pelo modelo e fornecer uma interface de consulta para esses arquivos. Então, deparei-me com o repositório imartinez/privateGPT. A configuração é bastante direta e bem documentada em PrivateGPT | Docs. O principal problema que tive foi com as versões do Poetry e do Python para executar o projeto. O projeto deve ser executado usando a versão 3.11. Mas, quanto mais eu tentava, ele sempre rodava com a 3.12. Esta é a solução alternativa que o fez funcionar.
$ brew install pyenv
# Any modern version python should do. I don't think Python 2 is required any more.
$ pyenv install 3.11.8
$ pyenv global 3.11.8
# Add pyenv to your PATH so that you can reference python (not python3)
$ echo "export PATH=\"\${HOME}/.pyenv/shims:\${PATH}\"" >> ~/.zshrc
$ source ~/.zshrc
# open a new terminal window and confirm your pyenv version is mapped to python
$ which python
$ python --version
Consulte também, para referência: Managing environments | Documentation | Poetry - Python dependency management and packaging made easy
Executando PrivateGPT
Para executá-lo, é necessário ter o servidor ollama em funcionamento. Isso pode ser feito no MacOS mantendo-o aberto em segundo plano, ou através do comando ollama serve.
Em seguida, em outra janela do terminal, execute os seguintes comandos a partir do diretório onde o privateGPT está. No meu caso, fiz um fork do repositório para poder fazer alterações nos arquivos sem preocupações.
# Pull the models, the LLM and embedding
ollama pull mistral # LLM
ollama pull nomic-embed-text # Embedding model
# Install dependencies
poetry install --extras "ui llms-ollama embeddings-ollama vector-stores-qdrant"
# Run privateGPT
PGPT_PROFILES=ollama make run
A interface deve estar disponível para ser visualizada abrindo o seguinte endereço no navegador 127.0.0.1:8001.
Ingerindo arquivos e consultas
Usei um artigo de uma pesquisa em plásticos biodegradáveis de Bagheri et al. A ingestão pode ser vista na imagem como a primeira linha. Depois de ingerido, posso consultar o arquivo para obter informações.
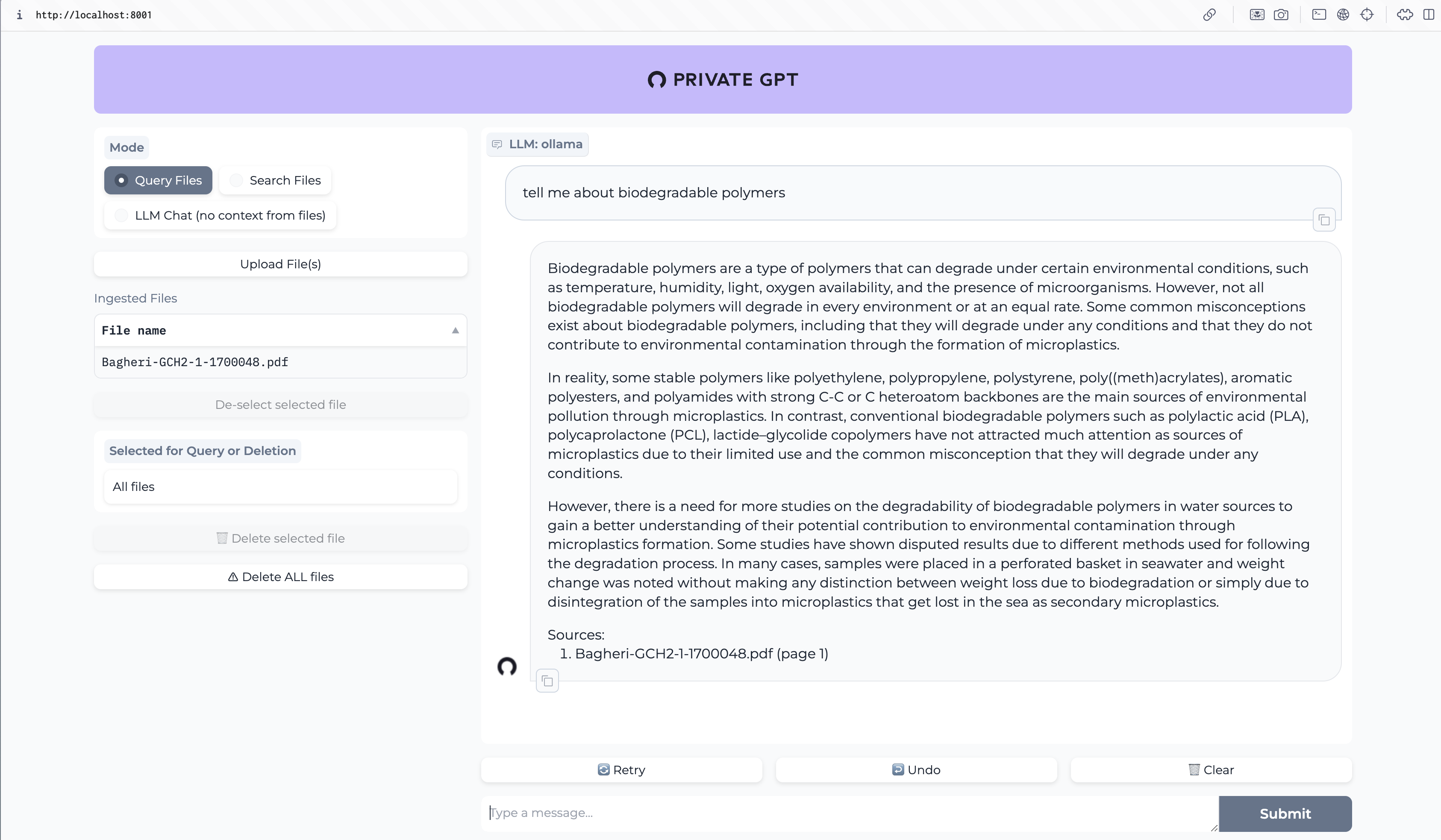
Fiz uma pergunta sobre plásticos biodegradáveis.
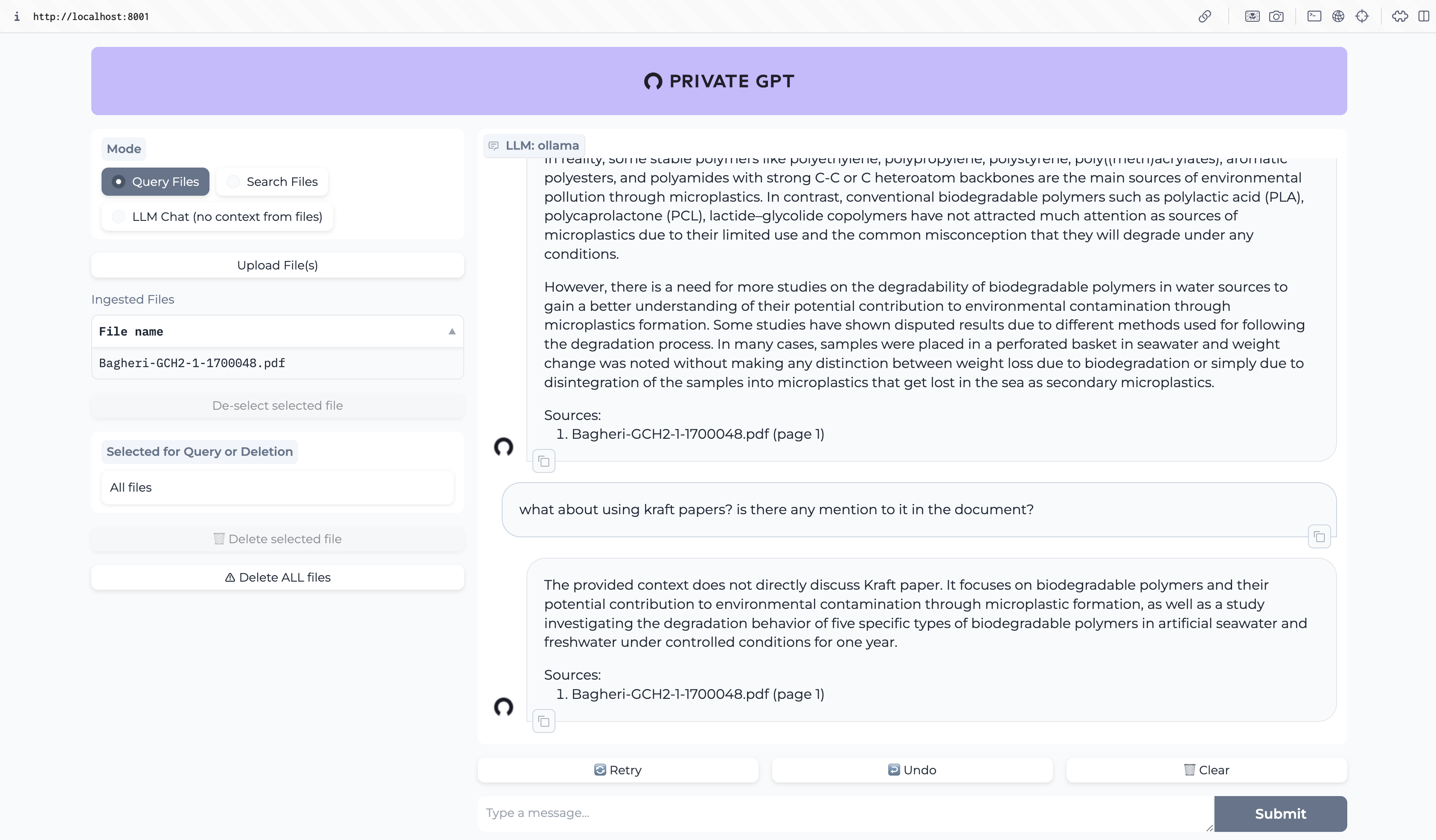
Então fiz uma pergunta sobre algo que não é mencionado no artigo para ver qual seria a resposta. Surpreendentemente, para mim, não alucinou. Simplesmente respondeu que o assunto não é discutido no artigo. Você pode adicionar uma grande quantidade de documentos. Já tentei com arquivos markdown e PDFs, mas há várias extensões de arquivo que são suportadas. Além disso, os arquivos ingeridos são mantidos no lugar até que você os exclua. E esta exclusão é apenas dos arquivos ingeridos. Não significa excluir o arquivo original.
Conclusão
Esta é uma configuração simples de um LLM privado e de código aberto. Tentei outros, usando AnythingLLM, e não funcionou, ou precisava de soluções alternativas para as quais não tenho tempo. Este foi o projeto mais fácil de configurar e há muito mais que pode ser feito com ele. Para mim, a integração com minhas notas do Obsidian é a próxima coisa que pretendo explorar.
Leia também:
- [Obsidian + Copilot]/pt/posts/10-obsidian-copilot/
- [Script para Atualizar o Open WebUI em um Proxmox LXC]/pt/posts/script-update-open_webui-lxc/
- [Como corrigir o bug de Modelos Personalizados Ausentes]/pt/posts/fix-custom-models-open-webui/
Você pode entrar em contato comigo sobre este e outros tópicos no meu e-mail [email protected] ou preenchendo o formulário abaixo.